Indexes are purely used to increase the
performance of your queries. The creation of indexes can be something resembled that of an index page on a textbook that can help you directly go to the
page with reference.
A similar concept applies while creating indexes
in SQL Server. Additionally, an index associated with a table is in-turn
latched up with the disk structure. Whenever, there is a call for an index, the
associated on-disk pointer retrieves the data quickly for high performance.
If your table is without an index, then
there happens to be a HEAP index. HEAP is nothing but a table without a clustered
index. In this situation, the data is stored randomly causing the whole table
scan whenever data retrieval operation happens. Keeping the HEAP index apart,
let’s dive to see the differences between a clustered and a non-clustered
index.
A table can consist of two types of
indexes:
1. Clustered Index
2. Non-Clustered Index
Clustered Index
A clustered index is mapped on to a table
that helps in sorting and storing the data rows with respect to key values. The
only possible way of storing the data in a sorted manner is while creating a
clustered index. And this is the actual reason behind why a table can have just
a single clustered index.
Let’s check the scenario of creating a clustered index on a table.
create table
[Clustered_Index_TEST]
(
ID int constraint
PK_Clustered_Index_TEST_ID primary key (ID)
,[Students]
nvarchar(50) null
,[Marks]
int
)
C2. Insert some records in [Clustered_Index_TEST] table
insert into
[Clustered_Index_TEST]
values (2,'Jason','97')
insert into
[Clustered_Index_TEST]
values (1,'James','54')
insert into
[Clustered_Index_TEST]
values (3,'Adams','68')
insert into [Clustered_Index_TEST]
values (6,'Tyler','71')
C3. Select records from [Clustered_Index_TEST] table where ID=2 for an example
select * from [Clustered_Index_TEST]
where ID =2

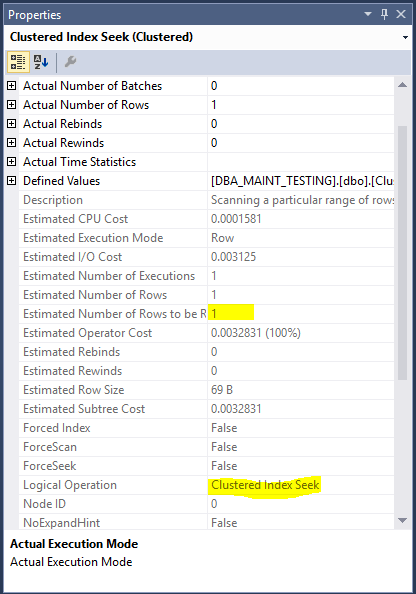
Observations: If you notice in the execution plan, the number of reads on the table is 1 and Logical Operation is Clustered Index Seek. We can conclude here saying that the clustered index on the ID column searched is going to be fetched directly using the index rather than a complete table scan.
Further, the table’s ID column was inserted in a jumbled manner, but the clustered index helped in sorting them.
POINT TO NOTE: Every table in SQL
Server created should have a mandatory clustered index created for better
performance.
Non-Clustered Index
Non-clustered Index is mapped on a table wherein the data rows are not in a sorted manner. The non-clustered indexes have a separate structure that holds key values. Every time there is a call for a non-clustered index, the respective key values fetch the data row that the index holds.
This scenario can resemble that of a website link. The link of a website resides at one place and the content page behind the link resides at another. Every time, we click the link (non-clustered index with key-value), the content page of the link is fetched (data rows where the non-clustered index with key points).
Let’s check the scenario of creating non-clustered index on a table.
NC1. Create a table as [NonClustered_Index_TEST]
create table
[NonClustered_Index_TEST]
(
ID int
,[Students]
nvarchar(50) null
,[Marks]
int
)
NC2. Insert some records in [NonClustered_Index_TEST] table
insert into [Clustered_Index_TEST]
values (2,'Jason','97')
insert into [Clustered_Index_TEST]
values (1,'James','54')
insert into [Clustered_Index_TEST]
values (3,'Adams','68')
insert into [Clustered_Index_TEST]
values (6,'Tyler','71')
NC3. Create a non-clustered index on ID column
create nonclustered index Ind_NCI_TEST_ID on NonClustered_Index_TEST(ID)
NC4. Select records from [NonClustered_Index_TEST] table where ID=2 for an example
select * from [NonClustered_Index_TEST]
where ID =2


Observation: If you notice from the execution plan, the number of reads on the table is 4 and the logical operation performed is Table Scan. It means that every time a record is fetched from the table, the SQL Server will scan the entire table rather than just one record.
POINT TO NOTE: Please have the practice to create a clustered index on a table. If exists already as a HEAP index on a table, please convert them to the clustered index for high performance.
You may find this helpful: 'Difference between Shared lock, Exclusive lock, and Update lock'










0 comments:
Post a Comment